 “Data-Driven Thinking” is written by members of the media community and contains fresh ideas on the digital revolution in media.
“Data-Driven Thinking” is written by members of the media community and contains fresh ideas on the digital revolution in media.
Today’s column is written by James Avery, CEO at Adzerk.
As ad blockers become more prevalent, it’s important to understand how they actually work and what they mean to publishers, ad tech companies and users.
What many don’t know is that some ad blockers are poorly written and can break websites.
The web is built upon a very simple mechanism: You request a URL in your browser, and a server returns an HTML file. The browser parses that file and most likely loads a number of other resources. It will load images, stylesheets and JavaScript. The browser loads these in order from top to bottom, and once it is done, you will have a fully rendered page.

Ad blockers work by using hooks in the browser to examine each request to a resource and block the resources it believes are advertising- or tracking-related.
This is where things get a little messy. How does the ad blocker decide what is advertising- or tracking-related? Most use a series of lists that include masks of which domains and patterns to block. Some lists are maintained by the ad-blocking companies, others by volunteers or a combination of the two.
The biggest issue with ad blockers comes from these lists. They are changed often – the ad blockers are set up to reload the list every couple of days – and they don’t do a very good job of just blocking ads or tracking.
Ad blockers can break the web. For example, here is a screenshot of a blog from marketing automation company Drip:
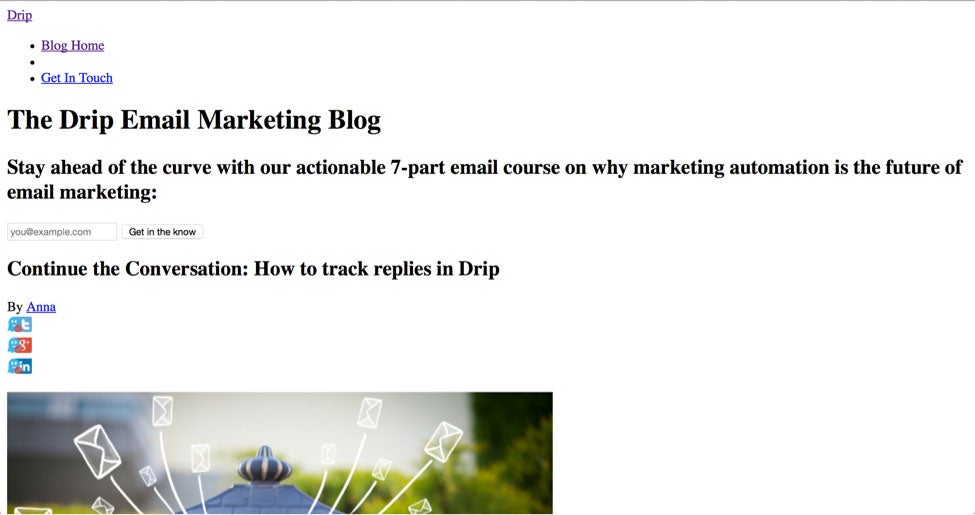

It looks like a web page designed in 1994. Here is what it should look like:
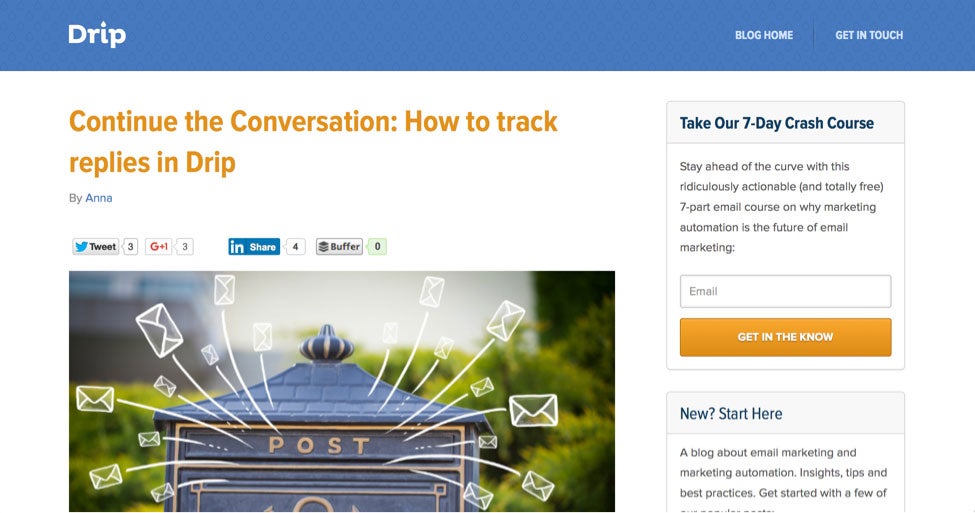
The reason for the discrepancy: Ad blocker Ghostery blocks all of the various stylesheets with an overly aggressive rule, as well as even jQuery, a well-known and harmless JavaScript framework:
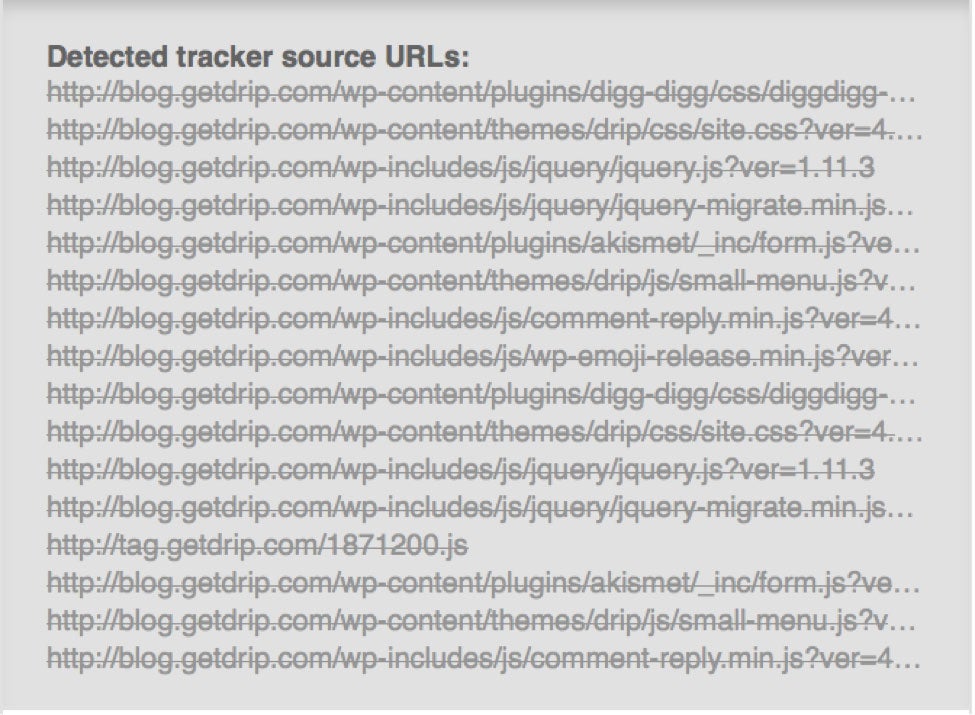
You can find similarly insane rules in many of these lists. For instance, a rule from the popular EasyPrivacy list maintained by AdBlockPlus blocks any request to a .com domain with an image named i.gif (with a query string). This is a pretty aggressive rule that has a high potential to break sites; very open rules like this have the potential to cause problems.
There are often cases of ads being only partially blocked, which is worse, because advertisers might get charged for these broken ads:
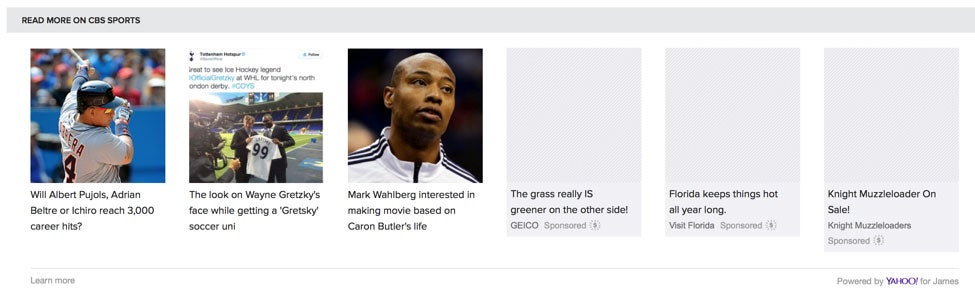
There was also a case of walmart.com not working with most iOS content blockers.
What is even more concerning to me as an engineer is that analytics domains, such as Loggly, Crazyegg and Mixpanel, are blocked by most ad blockers. These are valuable tools that help us build better software, and if they are blocked, tools for product managers and engineers to improve sites may be impacted. Here is a recent thread by a developer who spent months trying to figure out why a call didn’t work – only to later find out that it was his ad blocker.
Companies are trying to sell solutions to work around ad blockers, but they actually have the potential to make things much worse. If a publisher serves annoying ads from its own domain, the domain could still end up on block lists. Ad blockers might break the site or make it look or behave worse. Some users will figure it out, but many will just assume the site is broken and bounce.
So if publishers do decide to serve ads from their domain, they should try their best to serve nonintrusive or native ads that won’t encourage blocking. I have, however, still seen blockers block native ads that are well done and domain-served.
Can Blocking Get Better?
I think all of this begs the question: Should the industry work on its own ad blocker? The only people who definitely know if a request is an ad are the ad tech company or publisher serving it. For example, would it be better for a publisher to build its own blocker that at least wouldn’t break the rest of the site? I think that right now, the imperfectness of ad blocking is working in the industry’s favor – but that might not always be the case as the cat-and-mouse game continues.
There is an opportunity to work with browsers to improve some parts of blocking. Mozilla has started discussions around content blocking and, with its recent tracking protection, looks poised to start adding content-blocking functionality to the browser. This is something the industry should embrace: By working with browsers, we might be able to build a better blocking system that isn’t based on URLs and domains, but instead on a technical specification that won’t have these unintended effects. If users could dictate their privacy settings and have their browsers ensure they were honored, maybe we would stop ad blocking before it starts.
Ad Blockers Aren’t Lost
Some will say that as soon as someone installs an ad blocker, they are a lost pair of eyes and won’t come back. I don’t think this is true, because there is a very real cost to running an ad blocker. But users are willing to deal with the hassle of running an ad blocker to avoid the intrusive, annoying and overbearing ads they see across the web. The numbers tell us that users put up with these imperfect solutions because online ads and tracking have gotten that bad.
The good news is that blockers aren’t perfect, which means that if we can improve the default experience for users, we can possibly stop the growth of ad blockers and even roll it back. I wrote another column detailing the first steps I think we should take to do this. There is an incentive for users not to use ad blockers, but we need to make the web an awesome place, even without an ad blocker.
Follow Adzerk (@adzerk) and AdExchanger (@adexchanger) on Twitter.










