“Data-Driven Thinking” is written by members of the media community and contains fresh ideas on the digital revolution in media.
“Data-Driven Thinking” is written by members of the media community and contains fresh ideas on the digital revolution in media.
Today’s column is written by Tom Riordan, director of special operations at TubeMogul.
For decades, there’s a question that has punctuated marketers’ nightmares: “Did our advertising work?”
The advent of digital advertising was supposed to provide a respite from the years of relying on GRPs and subscription figures as proxies for effectiveness. Finally, marketers could ascribe a degree of certainty – or, at least, correlation – thanks to relatively new concepts such as cost per acquisition (CPA) and first touch, which were supposed to offer insights that went well beyond reach and frequency.
In the 10 years since, technological innovation has created new possibilities that would have made Erwin Ephron green with envy. Beacons and location-based technologies give brick-and-mortar retail outlets unparalleled insight into how their online marketing drives offline activity. Eye-tracking and heat maps give advertisers a window into user browsing behavior while respecting individual privacy. Even familiar concepts, such as survey retargeting, provide windows into how online ads affect brand awareness and purchase intent.

But it still feels like we have a tougher time than we should answering that question that keeps CMOs awake at night. Marketers remain hamstrung by models that, despite the improvement they represent over the pre-digital era, fail to properly account for all the variables necessary to accurately understand how marketing spend impacts the bottom line. There are three common biases that occur naturally within CPA-based models.
First, there is an in-market bias. Did an ad drive that sale? Or did the marketer just cookie someone who was already going to buy? Correlation does not equal causation. What many attribution models lack is a way to identify consumers that were already going to purchase. This identification is crucial because targeting certain audiences, including brand loyalists or people who have already visited a web page, naturally correlates with low CPAs.
In-market bias is further exacerbated by the fact that in-market audiences are more measurable than individuals higher up in the funnel. This is why search and direct-response perform so well in many attribution models.
There is also a low-rate bias. The easiest way to get a low CPA is to deliver media as efficiently as possible. Conventional logic argues that one can increase actions by increasing opportunities. This, however, may lead to “cookie bombing,” or deliberately delivering media as cheaply as possible without regard for media quality, in terms of viewability or publisher reputation, to audiences that are already on the path to conversion.
Consider the below scenario:
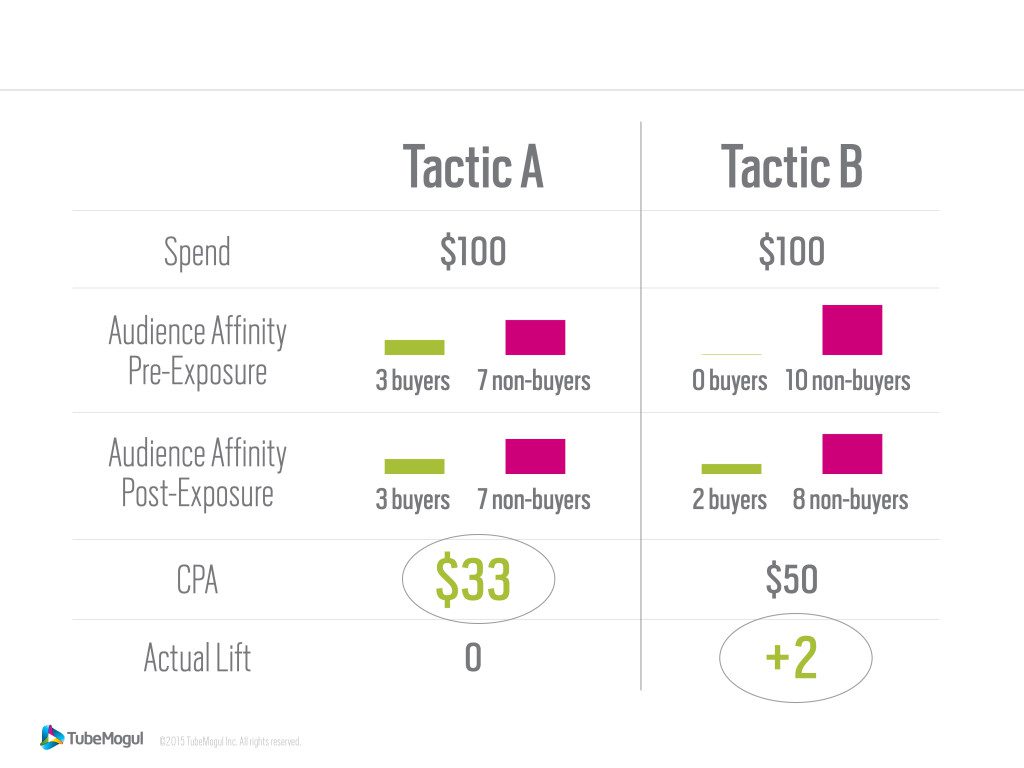
Without an established control group, CPAs are determined by a simple math equation relating audience targeting and media cost, not incremental revenue or actual ROI; while more impressions usually mean a more efficient CPA, it doesn’t always drive actual sales lift.
Finally, there is digital signal bias. While digital channels are estimated to comprise about 30% of total US advertising spend, the vast majority of sales still occur offline. Despite this, many advertisers only factor online sales into their attribution models simply because it’s easy to tie online spend to online actions.
After accounting for the aforementioned in-market and low-rate biases to help determine causality, marketers also need to include both online and offline sales in the “action” portion of their attribution measurements to get a truly representative picture of their online ad impact.
So what? Well, as Matthew McConaughey mused, sometimes, you gotta go back to move forward. Back to school, specifically. The solution is called experimental design, which posits that for any measurement to be valid, the experimenter needs to control for all the different variables that could affect outcome. Practically, advertisers must establish a baseline control group before they begin their campaign.
I would estimate that less than 10% of marketers actually do this. My guess is that most marketers don’t know that this is something they should do, while around 40% know they should but don’t know how. The culprit? KPI tunnel vision. Buyers are quick to focus on CPMs, viewability and other metrics with “easy button” implementations instead of taking the extra steps required to measure actual ad effectiveness in a statistically sound way.
The baseline control group helps marketers move past correlation and determine actual causality. It also helps them ascertain actual lift as opposed to just relative lift. Leveraging control groups graduates us from a CPA framework to a cost-per-incremental-action (CPIA) model, which focuses not on how many total sales occurred, but rather how many additional sales occurred that could be specifically attributed to an individual campaign.
These control groups are best achieved through using placebo ads, such as an ad unrelated to the actual brand that will not affect viewer sentiment. In place of placebo ads, marketers can use on/off testing (different media mixes in a single market), matched-market testing (different media mixes delivered with a pulsed flighting strategy) or random A/B creative tests to ascertain relative lift, which only tells a part of the story.
The widespread adoption of experimental design in digital buying is hindered by legacy – “the way things have always been done.” Digital buyers traditionally gravitate toward CPA models because targeting and optimization tactics historically favor correlation-based measurement. Many advertisers, especially major CPG companies, are “always on” and can’t just turn off a specific market. And onboarding offline sales data into an attribution model can be a daunting task regardless of technical prowess.
Change will not come overnight. But it starts with marketers thinking very critically about why exactly they wouldn’t want to test different ways to measure media effectiveness. CMOs that embrace the mindset of experimentation will find themselves much closer to finally closing the loop – and finally get a good night’s sleep.
Follow TubeMogul (@TubeMogul) and AdExchanger (@adexchanger) on Twitter.