 “The Sell Sider” is a column written by the sell side of the digital media community.
“The Sell Sider” is a column written by the sell side of the digital media community.
Today’s column is written by Paul Cimino, advisor and data lead for Prohaska Consulting and Altiscale.
Publishers’ and brands’ segment data may flow through their data management platforms (DMP), but since they don’t own the user IDs (the platform does), they technically don’t own the data.
While still a few years from becoming mainstream, data lakes can help publishers and brands create an environment where their data can be stored, nurtured, enriched and protected.
This first-party anonymous database allows publishers and brands to aggregate, intermingle and analyze all the data they own so they can monetize the significant value of this crucial asset.
Using a first-party data lake approach, a publisher can work with a brand or agency to segment, target and attribute an audience across media, regardless of how many intermediaries they work through. For instance, a sports publisher could sell a custom fan audience to an auto brand across screens and channels, enabling the auto brand to frequency cap and understand the effective CPM.

A Fragmented Landscape
To understand the potential for data lakes, we need to look at the current state of ad tech affairs.
Ad tech, and mar tech more broadly, are notoriously fragmented, complex and dynamic. The ad tech stack is a complicated animal dominated by third-party platforms. To create successful digital campaigns, data needs to be connected to third-party data platforms through third-party matching agents, as shown here in this basic view of the ad tech stack anatomy.
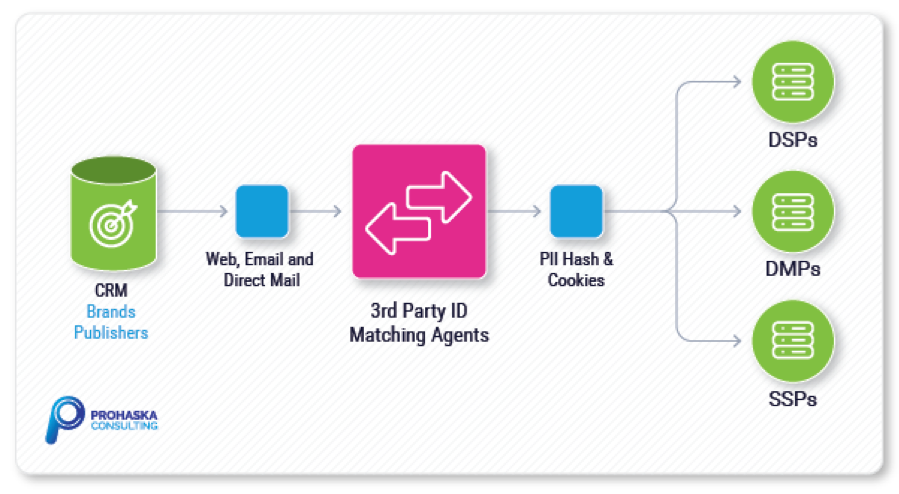
Although these third-party platforms are impressive, linking them together makes audience building, targeting and tracking very difficult. First-party data is the lifeblood of the ad stack, the raw material for user linkages. But the demand-side platforms (DSPs), DMPs and supply-side platforms (SSPs) add their own unique value in the form of segments, targeting and RTB, and they own the production system.
Once publishers and brands hand their assets over, the platforms’ revenue models rely on the data and its linkage to users to provide the critical mass they need to run their engines and do their job. There’s no question that it’s a symbiotic relationship – publishers and brands need the ad stack as much as the ad stack needs them.
But the major ad ecosystems are third parties that benefit from reimagining, repackaging and reselling that valuable first-party data and user linkage that publishers and brands put into their production systems.
Moving from one platform to another is not easy. DSPs, DMPs and SSPs understandably want to lock publishers and brands into using their third-party ID systems, which are not interoperable with others’ platforms for the most part and must be manually integrated.
Once the data is in their system, the identity data remains in their system for their use, even if a publisher’s or brand’s requirements change and they need to take their data business elsewhere. Starting over with a new provider will incur setup costs for moving data to a stack that might better suit new requirements. A more detailed view of this relationship shows the third parties as extremely fragmented data “islands.”

The Data Lake
In a data lake, publishers and brands can control all the data in their corporations, way beyond CRM POS, inventory and logistics. By developing a data lake they create a secure environment in which to store, own and manage the data that is the lifeblood of their companies.
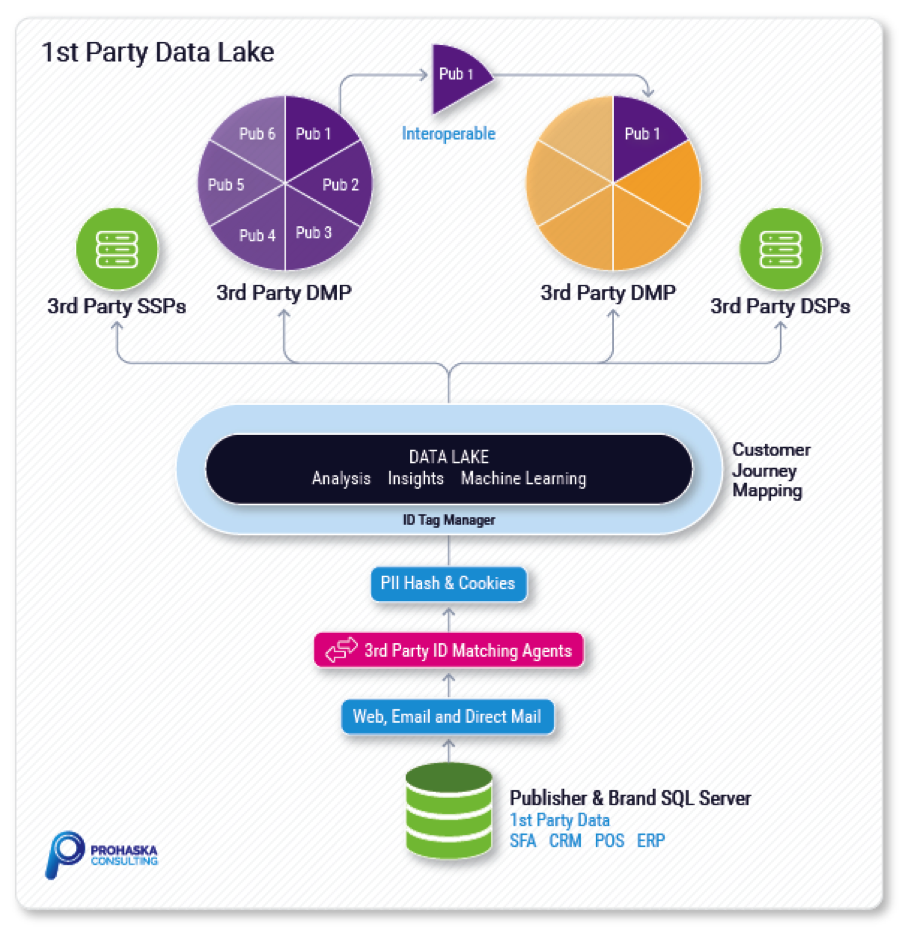
Constructing a data lake is not trivial. It involves the creation of two major pieces. First, there is a first-party ID or tag system that will populate their data lake and write to their domain, not to a third party.
Second, there is a big first-party database, typically based on cloud data technology such as Hadoop and capable of storing many petabytes of data.
Like any pixel system, the first-party ID and tag system must be integrated with all third-party providers. This ensures that third parties can redirect and call back to the data lake, enabling publishers and brands to capture all third-party transactions in near real time. This “master pixel” ID and tagging system populates and refreshes the data lake and makes it possible to analyze patterns in a much larger body of data.
This approach has several benefits. Aggregating all third-party IDs into a first-party data lake, for example, lowers costs because publishers and brands don’t have to re-link to users redundantly across each connection point.
The ability to mix all advertising data with all company data, including inventory, logistics and POS, can make cross-channel targeting and measurement more effective. It also sets the stage for customer journey mapping, where publishers and brands can find new prospects from general populations, convert them and gain their trust and loyalty.
Publishers and brands can also apply second-party data from each other directly to their first-party data lake to gain better insights. Data lakes are complementary to existing ad stacks and serve as a place to farm data that will make these partners much more effective.
The data lake enables publishers and brands to build game-changing data assets that enable brands to tell their stories to valuable publisher audiences across time and space – a long-held promise of digital marketing that is only now coming to fruition.
As we move into this next phase of internet advertising where data – not media –is the principal driver, it is essential for data originators to develop a first-party big data environment not only to keep track of their data but also to own their data supply chain.
Follow Prohaska Consulting (@TeamProhaska) and AdExchanger (@adexchanger) on Twitter.








